
Having based previous solution designs on SOA what will Architects need to do differently when adopting the Microservices approach? I thought I would look how the definitions of the two approaches match up. The first problem was there are plenty of definitions of each, so I have chosen to the definitions from a couple of the most well regarded publications: SOA Design Patterns (Erl 2008) and Building Microservices (Newman 2015). The following diagram illustrates how they align:
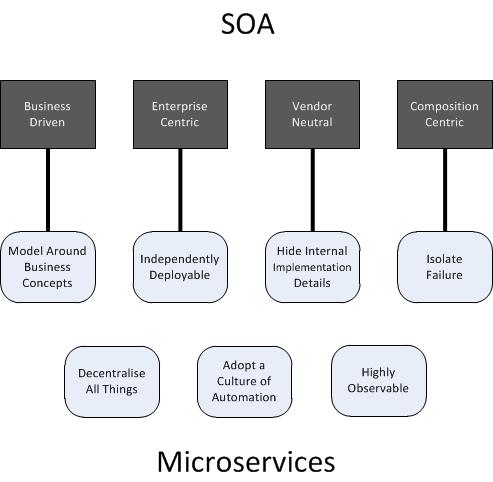
I looked at each of the Microservice principles to see if I could trace them back to a characteristic of SOA
Model Around Business Concepts is a straightforward match to the SOA characteristic of being Business Driven.
Independently Deployable services are a practical requirement for having an Enterprise Centric services architecture. If services were not independently deployable then service consumers would soon become frustrated at the need to co-ordinate changes. This is also true for services which depend on one another, the need to coordinate changes soon brings back the problems of monolithic designs, for example the scope of testing.
Hide Internal Implementation Details is not explicitly stated in Erl’s SOA characteristics but is a very central concept in many other definitions. If implementation details are not hidden consumers may be tempted to go directly to source, which defeats the value of having explicit service interfaces and, at its most extreme, would start coupling consumers to a specific vendor implementation, therefore no longer being Vendor Neutral.
Isolate Failure is a key requirement for a Composition Centric architecture because as more independent services are involved it becomes harder to guarantee they will all be available and operating correctly.
That leaves three Microservices principles that don’t, at least in some way, obviously tie back to Erl’s SOA characteristics.
Decentralise All Things, in its architectural meaning, suggests avoiding ESB and Orchestrations that may place too much business logic centrally. The need for such mechanisms is not a requirement of SOA but they are often discussed in SOA books and have, in my opinion, become associated with SOA architectures.
Adopt A Culture Of Automation although a good objective for an organisation wanting to be agile is, I would argue, not an architectural matter.
Again being Highly Observable is more of a feature related to implementation than it is an architectural design. That being said messages flows are highly observable and, whilst messaging is not required to be Service Oriented, this is how most services are consumed.
In conclusion I do think Microservices are a good extension of SOA but that the extension is more about the ecosystem around building and deploying services, rather than the resulting architecture. The most fundamental takeaway, for me, is the argument, or caution, against over-using ESBs or Orchestrations.
As always a good view from Martin Fowler.
 Follow
Follow
![2014.01.19 [IMG_1213]](http://www.gimeno.eu/wp-content/uploads/2014/01/2014.01.19-IMG_1213.jpg)

![2014.01.19 [IMG_1204]](http://www.gimeno.eu/wp-content/uploads/2014/01/2014.01.19-IMG_1204.jpg)

![2013.12.29 [IMG_1129]](http://www.gimeno.eu/wp-content/uploads/2013/12/2013.12.29-IMG_1129.jpg)
![2013.12.29 [IMG_1121]](http://www.gimeno.eu/wp-content/uploads/2013/12/2013.12.29-IMG_1121.jpg)
![2013.12.29 [IMG_0289]](http://www.gimeno.eu/wp-content/uploads/2013/12/2013.12.29-IMG_0289.jpg)

![2013.11.30 [IMG_1043]](http://www.gimeno.eu/wp-content/uploads/2013/11/2013.11.30-IMG_1043.jpg)
![2013.11.10 [IMG_0992]](http://www.gimeno.eu/wp-content/uploads/2013/11/2013.11.10-IMG_0992.jpg)