
The phrase ‘unstructured data’ has been around for some time and is typically applied to text, image and video. The complimentary phrase, ‘structured data’, has become synonymous with relational data. If we think about how much information is contained in some typical sources of data it would be something like this:
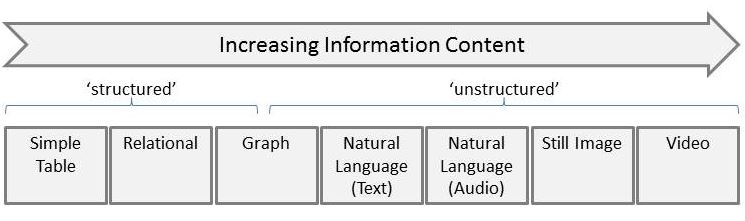
Simple tables are where I started my career – most data for an application stored in tables without necessarily normalising. Where there was related data we had to hand-code the joins! Relational data needs no introduction. Graph is interesting as it seems to be a way of making some ‘structure’ from what formerly was thought of as ‘unstructured’ especially when applied to text. The remainder then contain increasing amounts of information – natural language, images and video have far more complexity than relational data but have posed a problem for computers to process. The recent explosion in AI capabilities (thanks to Moore’s law) have started unlocking the values of this harder-to extract data.
I would argue that these phrases are misleading and that ‘unstructured’ sends the wrong message to non-technical colleagues or clients. The Wikipedia entry for unstructured data cites a study concluding around 90% of a corporation’s data is ‘unstructured’. As IT professionals we should be encouraging more desire to exploit this data. I would like a better terms for it, how about ‘Rich Data’? And so what to call ‘structured’ data – I did think ‘Simple’ but that makes it sound it should be cheaper to deal with than is actually is. So, to conclude, how about ‘Structured’ and ‘Rich’ or is there a better term out there?
 Follow
Follow![2013.12.29 [IMG_0289]](https://www.gimeno.eu/wp-content/uploads/2013/12/2013.12.29-IMG_0289.jpg)
