![2013.05.26 [IMG_0514]](https://www.gimeno.eu/wp-content/uploads/2013/09/2013.05.26-IMG_0514.jpg)
When approaching a migration it is tempting to try and do the simplest thing that could possibly work, most likely a re-key or one-off ETL , because any code or process created for the migration is probably going to be discarded once complete. Assuming a code solution is proposed then it’s probably going to look like this:
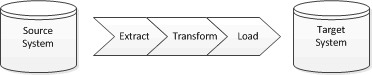
So who is going to do the work? If it’s a single team then maybe this approach will work but if there are two teams: one focussed on the source system and one focussed on the target system then the question is who works on what, most likely the answer is the sending system team gets to do the extract and the target system team does the load but who does the transform?
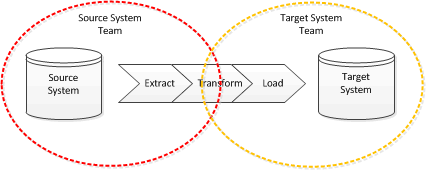
Working on the transform is probably going to take both teams. This has some problems:
- both teams need to understand each-others data-model which, of course, can be very complex especially if one party forgot the most important step of normalisation.
- codes need to be mapped and this is often not a one-to-one relationship
- the target system team need to understand where data might be missing in the source system
- the target system team need to understand what to do about data quality problems in the source system
- reconciling the migration will be difficult if both data models are complex.
The answer: introduce an intermediate data model
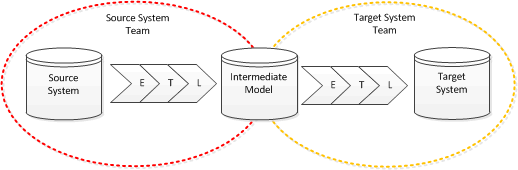
The main design consideration of the intermediate data model is that it should be clear and simple to understand, there should be no ambiguity; it has the following features:
- The structure is as simple as possible: code tables are denormalised and merged back into the major entities; user management data can be removed along with system log or other management tables. Both teams are likely to need to come together to agree the structure because this is the common representation of the data from both systems.
- The structure does not need to match either the source or target system (if it does maybe you don’t need this step).
- All codes are turned into a description, e.g. replace a status code of “1” with ”Active”
- Column names for tables should be as descriptive as possible.
- Optimisation for performance involving changes to structure should only be considered if absolutely essential.
- Missing data should be explicitly marked as such.
- Data quality issues should be resolved by the source system team as part of their ETL.
The advantages of using the intermediate data model are:
- Each team can focus on their area of expertise
- There is less scope for ambiguity leading to mistakes and subsequent rework
- Reconciliation can be split into two, simpler, reconciliations (source to intermediate and intermediate to target)
- The target system team are not bound to the source system team making data available, they should understand the intermediate model well enough to generate test data
- The intermediate data model serves as an archive for subsequent audit or enquiries needing to understand how data was created in the target system
It is especially worth considering using an intermediate data model if the migration is split into phases, or there will be multiple source systems over time, as it can be extended and modified to represent any unique requirements at each phase, or source system, rather than having to understand all of these complexities at one time.
These advantages are also applicable to integrations that follow the ETL model.
 Follow
Follow![2012.01.07 [IMG_8721]](https://www.gimeno.eu/wp-content/uploads/2013/09/2012.01.07-IMG_8721.jpg)
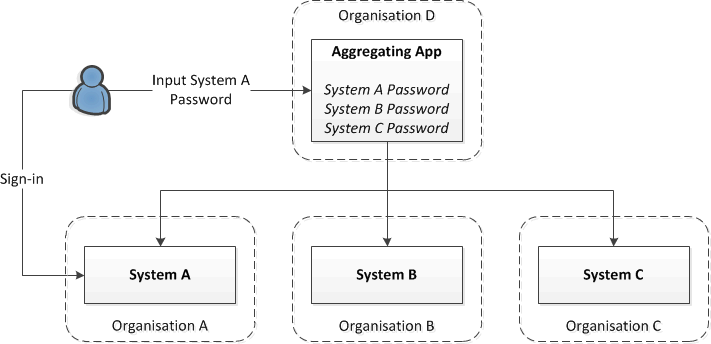
![2011.12.24 [IMG_8480]](https://www.gimeno.eu/wp-content/uploads/2013/09/2011.12.24-IMG_8480.jpg)
![2012.01.13 [IMG_8794]](https://www.gimeno.eu/wp-content/uploads/2013/09/2012.01.13-IMG_8794.jpg)